源起 & 說明
起心動念編纂這本「講義」的時候,正值我準備 APCS 考試期間,當時也正在就讀高中,考量到時間上的不足,我邀請 3 個人一起參與,所以,作者總共有 4 個人,而本篇貼文所摘錄的是我所創作的部分。
作者序
演算法與資料結構一直以來都是程式設計中最重要的部分。然而許多的書籍在介紹時,出於篇幅考量,字句精簡,以致晦澀難懂。本書旨在對於演算法及資料結構進行詳細的介紹,避免初學者遇到與我相同的困境,因而花費許多時間。雖說是競賽入門,然我仍有計畫放一些進階的資料結構與演算法。
後續我盡可能會將所有題目放在 ZeroJudge 的課程裡,方便大家測試自己的程式碼,也方便除錯。
(參加課程方式。從使用者選單->「參加課程」->課程代碼:a7HcCs)
這本書作為我程式設計學習的其中一個指標,也是我自主學習計畫的內容。希望能幫助到一些在資料結構與演算法的學習與運用上不知如何進展的人。
作者:李尚哲、余光磊、戴偉璿與李卓岳。
本教材歡迎分享使用,僅須註明出處,惟不得作營利用途。
樹狀樹組-BIT
快速求取區間和的助手
回顧
還記得前綴和嗎,他也是用來求區間和的,但你應該會發現,若當中有一個值需要被修改,那整列都會被動到。
以下是一個比較表,了解BIT強大之處
| 資料結構 | 查尋區間和 | 單點修改值 |
|---|---|---|
| 純陣列 | \(O(n)\) | \(O(1)\) |
| 前綴和 | \(O(1)\) | \(O(n)\) |
| BIT | \(O(log(n))\) | \(O(log(n))\) |
用途 & 概念
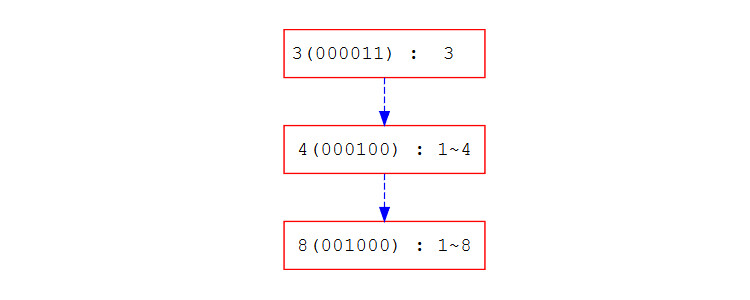
BIT用於在快速求取區間和的同時,又能保證快速修改。感覺像是陣列與前綴和的優點結合下的產物,不過其複雜程度也是三者之中最高的。以下為示意圖,其中數字代表它儲存的區間。

如果想要知道1~5的和,可以查詢1~4+5。以下為查詢所需區間表。
| 1 | 1~2 | 1~3 | 1~4 | 1~5 | 1~6 | 1~7 | 1~8 |
|---|---|---|---|---|---|---|---|
| 1 | 1~2 | 1~2 & 3 | 1~4 | 1~4 & 5 | 1 |
1 |
1~8 |
可以發現,在元素數量為8時,最多會需要查詢3個區間就可以得到1~n的值,接著就像前綴和那樣,用1~R - 1~(L-1)就可以求出所有區間的和了。
實作
BIT一般都是用陣列實作,用區間最大值作為存放位置(例如1~4放在4)。那搜尋與修改呢?這部分就比較複雜了,需要了解一些二進位制,如果你已經理解二進位制了,那就繼續往下看吧。
二進位表
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 000001 | 000010 | 000011 | 000100 | 000101 | 000110 | 000111 | 001000 |
lowbit
lowbit是在二進位下右邊看過來最前面的1,例如:6(000110)就是2(000010),一樣提供一個表
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 000001 | 000010 | 000011 | 000100 | 000101 | 000110 | 000111 | 001000 |
| 000001 | 000010 | 000001 | 000100 | 000001 | 000010 | 000001 | 001000 |
查詢
可以發現,\(x\)重複\(-lowbit(x)\)會變成0,且途中會經過所有需要的區間。以7為例

只要將所有經過的區間加在一起,就可以得到區間和了。這也呼應為何他查尋的複雜度為\(O(log(n))\),因為\(n\)只會有\(log(n)\)個\(bit\)。
修改
這樣最多也是\(O(log(n))\)。也可以發現\(lowbit\)的重要性。
程式碼
1 |
|
習題
Q-13-1 區域調查(POJ.1195 Mobile phones 改編)
題目敘述 :
給一個矩陣 T(1,1), T(1,2),…. T(N,M),求 T(x1,y1) 到 T(x2,y2) 的總和 或者是修改 T(x1,y1) 的值
輸入說明 :
每組輸入的第一行會有兩個正整數 N Q ( 1 ≦ N ≦ 250, Q ≦ 50,0000)
接下來會有 N 行,每行上會有 N 個元素 M ( 0 ≦ M ≦ 32767 )
接下來會有 Q 行,倘若第一個數字為 1,則接下來會有四個數字
x1 , y1 , x2 , y2, 1 ≦ x1 , y1 , x2 , y2 ≦ 250
請輸出元素 \(S={( x , y ) | x1 ≦ x ≦ x2, y1 ≦ y ≦ y2 }\)符合的所有元素總和
倘若第一個數字為2,則接下來會有三個數字
x1 , y1 , V, 1 ≦ x1 , y1 ≦ 250 , 0 ≦ V ≦ 32767,
請修改 ( x1 , y1 )= V ; 此行不必輸出
輸出說明 :
若為調查,則輸出區域中的元素總和,若為修改,則不必輸出
範例輸入 1 :
1 | 5 10 |
範例輸出 1 :
1 | 2 |
Q-13-2 2D rank finding problem(98學年度中投區資訊學科能力競賽)
題目敘述 :
二度空間上的排名計算問題(2D rank finding problem):給定二度平面空間(2D)上的點A = (a1,a2)與點B = (b1,b2),其大小關係定義為若A > B 若且唯若 a1> b1 且 a2 > b2 ;亦即A點在B點的右上方。如下圖中,B >A, C>A, D>A, D>C, D> B。值得注意的是,並非任意兩點均可以決定大小關係,如下圖中的點A與點E,點D與點E等,無法決定這兩點的大小關係故為無法比較(incomparable)。給定N個點(x1,y1), (x2,y2), …, (xn,yn),定義某一個點的排名(rank) 為所給的點集合中,比該點小的點的個數。
設計一個程式,從檔案讀取點的名稱與座標,計算出在所給定的集合中,所有點的排名值。
輸入說明 :
有多組測試資料
每組的第一行有一個數字N ( 1 ≦ N ≦ 10000 )
接下來會有N行,每行上會有兩個數字 x y ( 1 ≦ x , y ≦ 1000 )
輸出說明 :
請按照輸入的順序,求出對於 ( x , y ) 有多少個點 ( a , b )
在它的左下方 a < x , b < y
範例輸入 1 :
1 | 5 |
範例輸出 1 :
1 | 2 |
Q-13-3 低地距離(2020年10月APCS)
題目敘述 :
輸入一個長度為 2n 的陣列,其中 1 ~ n 的每個數字都剛好各 2 次。
i 的低窪值的定義是兩個數值為 i 的位置中間,有幾個小於 i 的的數字。
以 \([3, 1, 2, 1, 3, 2]\) 為例,1的低窪值為 0, 2 的低窪值值為 1, 3 的低窪值為 3。
請對於每個 1 ~ n 的數字都求其低窪值(兩個相同的數字之間有幾個數字比它小),輸出低窪值的總和,答案可能會超過 C++ int 的上限。
輸入說明 :
第一行有一個正整數 n
第二行有 2n 個正整數,以空格分隔,保證 1 ~ n 每個數字都恰好出現兩次。
1≤n≤100000
輸出說明 :
輸出 1 ~ n 每個數字的低窪值總和。
範例輸入 1 :
1 | 3 |
範例輸出 1 :
1 | 4 |
線段樹
於競賽而言強大的工具。
用法 & 概念
線段樹除了可以用來快速解區間和問題,還可以用來執行許多與區間有關的操作。大致上用以下方式建構區間
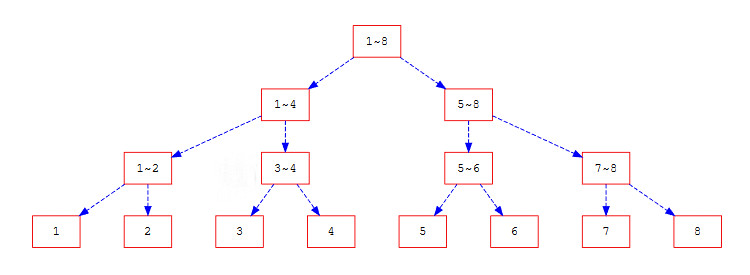
每個區間視情況放不同的數值,例如:最大/小,或是區間總和等。
接著,每個區間就都可以分為\(O(log(n))\)個區間,例如2~7可以分為2, 3~4, 5~6, 7

查詢時皆以最大區間為出發點,例如上圖就會是從1~8這個區間開始,如果要查詢的區間是2~7。因為1~8這個區間並沒有完全包含2~7,因此需要往下遞迴,分成1~4和5~8再次查詢。
接著,因為1~4和5~8仍然沒有完全被2~7包含,因此要再次遞迴,這次是分解成1~2,3~4,5~6以及7~8。
這次3~4和5~6都有被完全包含,因此可以直接回傳這個區間的值。而1~2和7~8還是沒有。所以這兩個區間還要再次向下查詢。
查詢時最重要的是,若區間完全被包含就直接回傳,若完全沒被包含就不往那邊搜尋,否則再將區間分成兩塊向下遞迴。
實作
可以發現他是一顆二元樹,於是我們有兩種做法:指標型與陣列型。以下實作以區間總和為範例。
指標型
請詳讀程式碼,我盡可能詳細註解
1 |
|
陣列型
設根節點idx為1,在完滿二元樹中,左子樹就會是\(idx \times 2\),右子樹就是\(idx \times 2+1\)。
1 |
|
懶人標記
以上的實作方法都只能用於單點修改,而若需要區間加值的話則會很費時,因此有人想到一個方法:若要修改的區間剛好完全包含線段樹上的某個區間的話,就可以先在上面打一個標記。等到需要動到他下面的子區間再向下放。這樣的話區間加值也可以從 \(O(nlog(n))\) 進步到 \(O(log(n))\) 。
實作
指標型
請詳讀程式碼,我盡可能詳細註解
1 |
|
習題
Segment Tree 練習(ZJe409)
題目概述 :
將 \(A[x]\)的值更新為 \(y\)
要查詢 \(A[X]\)~\(A[Y]\) 之中最大值\(maxA\)及最小值\(minA\)的差
輸入說明 :
第1列有兩個正整數 \(k\) \(m\) ,第2列有 \(k\) 個正整數, 請讀入放至 \(A[1..k]\)
接著讀入第3列的 \(N\) \(Q\) 兩個正整數,呼叫所附的產生測資程式 gen_dat()
以上 \(5<k \leq n, 5<m<1000\)
然後就是解題,依\(C,X,Y\)陣列的值 執行更新或查詢
輸出說明 :
若為調查,則輸出區域中的元素總和,若為修改,則不必輸出
範例輸入 1 :
1 | 10 541 |
範例輸出 1 :
1 | 328 |
戰術資料庫(110宜中資訊社校內賽pF)
題目敘述 :
要求能在一個陣列中做以下操作
- 搜尋區間和 \(find sum\) \((l)\) \((r)\)
- 搜尋區間最大和最小值 \(find\) \(max/min (l)\) \((r)\)
- 單點加減值 \(plus/minus\) \((position)\) \((k)\)
輸入說明 :
輸入第一行有一個數字 n, q ,下一行有 n 個數字,緊接著有 q 筆操作,可能為以下五種
- 搜尋區間和
- 搜尋區間最大和最小值
- 單點加減值
相鄰數字間以空白隔開。
\(n, q \leq 100000 , a[i] \leq 100000\)
輸出說明 :
對於每個搜尋指令做出回答
範例輸入 1 :
1 | 7 10 |
範例輸出 1 :
1 | 5 |
2022/1/10
樹堆(Treap)
Treap 是一個隨機平衡的二元搜尋樹,這裡所說的 Treap 是以 merge/split 的方式實作的,這樣實作的 Treap 有很多好處,我們先說明他的基本規則,以及 merge/split 函式(function)在做什麼,結著說明如何實作。
樹堆的名稱來由是 樹(Tree) 和 堆積(Heap) 結合而成,每個節點會至少存放兩個數值 val,pri , val (也有人叫他 key)就是內容,而 pri 則是用以平衡。
規則與前置作業
- 所有節點的 pri 值必須比他的左右子樹小(大也可以)
- 樹上的 val 滿足 \(“二元搜尋樹”\) 的性質
為了避免有人忘記什麼是 \(“二元搜尋樹”\) 的性質,以下用一個我出過的題目說明。
Safe Sorter
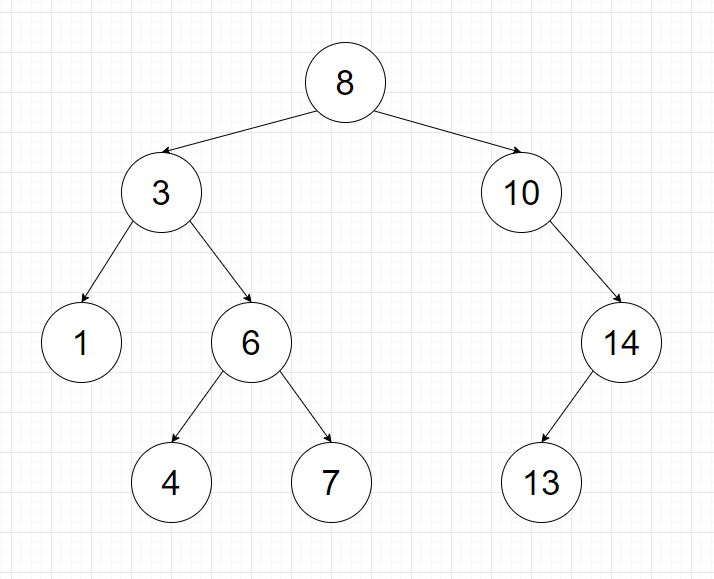
- 如果該節點還沒有任何保險箱,此保險箱就會佔據該節點
- 否則若這個要放入的保險箱裡面的金塊比在該節點的保險箱還要多,他會被往右邊送
- 否則就往左邊送
- 必須送到他占用一個節點為止
以上圖為例
- 第一個放進來的保險箱有 8 個金塊
- 第二個有 10 個,因此他被放在右邊
- 第三個有 14 個,因此第一步會先往右送,發現右邊的節點也有保險箱了,因而再次被往右送
- 第四個有 3 個,於是被放在左邊
- 其他依此類推
而所謂隨機平衡就是他的平衡方式來自所有節點被賦予的一個隨機的 pri 值。
Treap 當中最重要的就是以下兩種操作
- merge(a,b) : 將兩顆樹 a, b 合併。前提 : a, b 滿足所有在 a 裡面的節點所存放的值皆小於所有在 b 裡面的節點
- split(a,b,p) : 將一棵樹分成 a, b 並同時滿足 a 中的值皆小於等於 \((\le)\) p , 而 b 中的值皆大於 \((>)\) p
兩者詳細步驟是依照遞迴定義的,如下。
Merge
- 如果 a,b 至少其中一個是空指標,回傳非空的那一個 (兩個都空救回傳空指標)
- 否則為了同時維持 BST 和 heap 的性質,我們先判斷哪一個的 pri(priority) 值更大,我的實作是將 pri 值小的放上面 (較接近樹根的位置)
- 如果 a 的 pri 值較小,我們會回傳 a 作為呼叫此函數的樹的根,不過在此之前,我們要先決定 a 的右子樹 (因為 b 也還沒被合併完) ,所以要向下遞迴
- b 的情況剛好相反,因為 b 裡面的值都大於 a 裡面的值
實作
1 | node *merge(node *a,node *b){ |
Split
split 較為複雜,因為同時要滿足 Treap 的兩種性質
- 若 T(要被分割的 Treap) 為空指標的話,代表整棵樹都被分完了,因此將 a,b 都設為空指標。
- 否則一樣要分成兩個條件 : T 的根結點的值小於等於 p ,和大於 p
- 如果 T 的根結點的值小於等於 p ,選擇將 T 的根結點與他的左子樹給 a 並繼續向下分解 T 的右子樹給 a 的右子樹與 b
- 否則將 T 的根結點與他的右子樹給 b 並繼續向下分解 T 的左子樹給 b 的左子樹與 a
實作
1 | void split(node *T,node *&a,node *&b,int p){ |
名次樹
首先介紹一下名次樹,名次樹是透過在節點內多存一個數值 \(\to\) 子樹大小(size),以實現更多功能,例如 : k 在這棵樹裡面排第幾,刪除比 k 大的第一個數,還有排名第 k 的樹為何等。
為了在 Treap 中實現這個功能,我們要多實作兩個函數 \(\to\) pull & SplitBySize(splitSz)。
首先,我先將節點完整的 struct ,還有尋找某個指標底下的樹的 size 的函式寫出來,方便後續講解。順帶一題,為了維持名次樹的正確性,每次只要樹有經過更動就要 執行 pull 。
1 | struct node{ |
SplitBySize
這個函式會與 Split 有點像,差別在於分開的依據不同, SplitBySize 會將整棵樹分為 a, b , 其中 a 存有前 s 小的所有數, b 則存剩下的。詳細步驟如下。
- 與 Split 相同,若 T 為空則表示分完,將 a,b 都設為空指標
- 否則如果 T 的左子樹的元素個數不到 s ,將 T 和他的左子樹都給 a ,然後繼續從 T 的右子樹當中切出 s-( T 的左子樹大小)-1( T 自己) 個元素給 a 的右子樹
- 否則將 T 和他的右子樹都給 b ,然後從 T 的左子樹當中切出 s 個元素給 a
實作
1 | void splitSz(node *T,node *&a,node *&b,int s){ |
隨機數
C++ 本身就有內建隨機函式可供取用。就直接放在下面供大家參考。
1 | // 簡單作法,但可能被 hack |
1 | // 較長,但較不易被破解 |
基本功能
有了這些函式之後,後面的大多數操作都會變很簡單,舉凡插入(insert),刪除(erase),尋找(find) 等等。因為他們都可以用 merge and split 湊出來。而且很多功能甚至不只有一種實作方法。讓我們看下去。
Insert
insert 可以被簡單地分成幾個步驟。假設我要插入的數字為 v 。
- 將整棵樹(我都存在 rt 指標中) 切成小於等於 v 和大於 v 的兩棵樹 rt, b
- 另外用 v new 一個節點 a(v) 出來 (不會動態記憶體分配的可以先去複習一下)。
- 合併 rt 和 a ,並將合併後的樹給 rt
- 合並 rt 和 b ,並將合併後的樹給 rt
實作
1 | void insert(int v){ |
Erase
Erase 一樣可以被簡單地分成幾個步驟。假設我要刪除的數字為 v 。
1. 刪除所有等於 v 的數(整數才可以)
- 將整棵樹(我都存在 rt 指標中) 切成小於等於 v 和大於 v 的兩棵樹 rt, b
- 再將 rt 指向的樹切成小於等於 v-1 和大於 v-1 的兩棵樹 rt, a
- 刪除 a 整棵樹
- 合併 rt 和 b ,並將合併後的樹給 rt
2. 刪除一個等於 v 的數(整數才可以)
- 將整棵樹(我都存在 rt 指標中) 切成小於等於 v-1 和大於 v-1 的兩棵樹 rt, b
- 再將 b 指向的樹切成左邊一個元素,剩下都放右邊的 b, a
- 刪除 b
- 合併 rt 和 b ,並將合併後的樹給 rt
實作
1 | // 這個函式是先刪除左右子樹,再刪除自己,並透過遞迴來刪掉整棵樹。 |
Count
Count 還是可以被簡單地分成幾個步驟。假設我要數的數字為 v 。
- 將整棵樹(我都存在 rt 指標中) 切成小於等於 v 和大於 v 的兩棵樹 rt, b
- 再將 rt 指向的樹切成小於等於 v-1 和大於 v-1 的兩棵樹 rt, a
- 用一個變數將 a 的 size 存起來
- 合併 rt 和 a ,並將合併後的樹給 rt
- 合併 rt 和 b ,並將合併後的樹給 rt
實作
1 | int count(int v){ |
Kth Small Element
假設我要找第 p 小的數字。
- 將整棵樹(我都存在 rt 指標中) 切成左邊 p 個元素,剩下都放右邊的 rt, b
- 再將 rt 指向的樹切成左邊 p-1 個元素,剩下都放右邊的 rt, a
- 用一個變數將 a 的值存起來
- 合併 rt 和 a ,並將合併後的樹給 rt
- 合併 rt 和 b ,並將合併後的樹給 rt
實作
1 | int kth(int v){ |
你以為只是平衡樹嗎?不不不,祂可厲害了
進階功能
如果我們將整棵樹的中序遍歷當成序列的順序的話(如下圖),我們可以實現需多更強大的功能。可以說,線段樹能做到的事 Treap 都可以做到,但 Treap 甚至可以做到許多線段樹做不到的事。
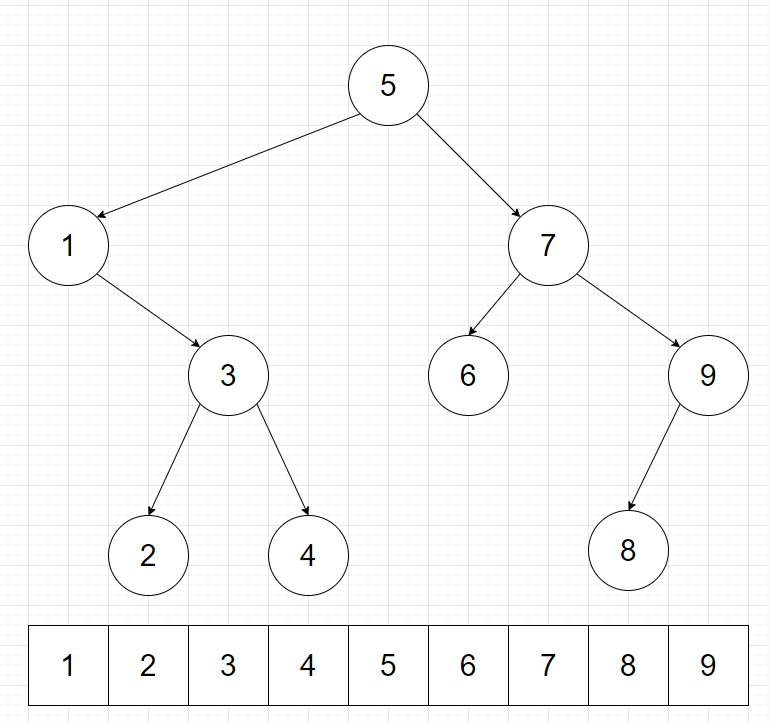
而且,此時我們可以把 key 拔掉。然後只使用 splitSz 和 merge 。
Insert
假設我希望插入的數字位於第 p 個,且值為 v 。
- 將整棵樹(我都存在 rt 指標中) 切 p-1 個給 rt ,其他剩下的分給 b
- 另外用 v new 一個節點 a(v) 出來
- 合併 rt 和 a ,並將合併後的樹給 rt
- 合並 rt 和 b ,並將合併後的樹給 rt
實作
1 | void insert(int p,int v){ |
Erase
假設我要刪除第 p 個數
- 將整棵樹(我都存在 rt 指標中) 切 p-1 個給 rt ,其他給 b
- 再將 b 指向的樹切一個給 b 剩下給 a
- 刪除 a
- 合併 rt 和 b ,並將合併後的樹給 rt
實作
1 | void erase(int p){ |
區間操作
在介紹區間操作之前,我們還需要在節點上加入更多的資訊和函式,所以 node 裡面會有更多程式碼。
1 | const int INF=0x3f3f3f3f |
同時,我們在原來的 merge/split 操作程式碼中,都要加上 push ,具體位置如下
1 | struct Treap{ |
接下來的操作都是把區間切下來,做完我要做的事,再接回去就可以了。
區間查詢(極值、總和)
假設現在要查詢 l~r 的區間
- 從 rt 切下 r 個節點給 rt ,其它給 b
- 接著從 rt 切下 l-1 個節點給 rt ,其餘給 a
- 此時 a 就存有區間 \([ ; l, , r ; ]\) ,而他上面的 sum, mx, mn 就會是這個區間的總和、最大值,以及最小值
- 最後先按照順序把它合併,再回傳答案即可
實作
1 | int query(int l,int r){ |
單點修改
先將所要修改的位置切下來,在修改完後記得要 push 。
1 | void modify(int p,int v){ |
區間操作
假設現在要對 l~r 的區間進行操作
- 從 rt 切下 r 個節點給 rt ,其它給 b
- 接著從 rt 切下 l-1 個節點給 rt ,其餘給 a
- 此時 a 就存有區間 \([ ; l, , r ; ]\) ,直接對他操作就可以了
- 最後先按照順序把它合併
實作
1 | // 區間反轉 |
特殊功能
Count \([ ; l, , r ; ]\)
在一棵作為二元搜尋樹的 Treap 中,計算介於 l 到 r 的元素數量
基本上就跟上面區間查詢相同。只是切割依據不同。
實作
1 | int count(int l,int r){ |
Sum \([ ; l, , r ; ]\) (rank)
在一棵作為二元搜尋樹的 Treap 中,計算介於第 l 小到第 r 小的元素總和
同樣就跟上面區間查詢相同。只是元素排列方式不同。
實作
1 | int Sum(int l,int r){ |
解構式
對於多筆測資,可能會需要釋放記憶體。由於 Treap 二元樹的特性,可以透過遞迴刪除整棵樹
1 | struct Treap{ |
重載輸入輸出
要前中後序都可以
1 | void print(node *n,ostream &output){ |
一些 STL 的常見函式
1 | int size(){ |
建構式
有了上述的 STL 常見函式之後,就可以很方便的寫建構式了。
1 | Treap(){ } |